
I Trained GPT in Google Sheets
Understanding transformers by building one the hard way

I spent a month teaching Google Sheets to train a GPT model.
9 hours per training run. 19,000 parameters crawling through cells. Formula recalculations that made my laptop fan feel like it was Austin, TX in July. This was probably stupid.
But somewhere around week 3, watching numbers accumulate in cells I could actually click on and inspect, something clicked that never clicked before.
The Problem
I’ve shipped deep learning models. Built agentic AI systems. LoRA-tuned GPTs. Read Attention Is All You Need multiple times.
But I didn’t fully understand transformers — the architecture that the “T” in GPT (Generative Pre-trained Transformer) actually stands for.
There’s knowing how something works and understanding how it works. When you call .backward() in PyTorch, you’re abstracting away the entire learning process. Gradients flow. Weights update. You watch a loss curve decline.
That’s powerful for building systems. It’s terrible for building intuition.
Others have built transformer demos in spreadsheets (example, another). Those demonstrate the architecture with random weights. I wanted to know: could you actually train one? Implement backpropagation, update weights through gradient descent, and watch the model learn from scratch?
So I made Google Sheets do something it was never designed to do. Some people will say I could have spent this time vibe coding yet another B2B SaaS. Maybe Zuck will reach out with a $10m offer. We shall see.
Transformers in 60 Seconds
If you’re familiar with transformer architecture, skip this. If not, here’s what you need to know:
Transformers are pipelines that alternate between data converters and pattern finders. The whole architecture is repeatedly transforming how data is represented until the structure of meaning becomes trivial to detect.
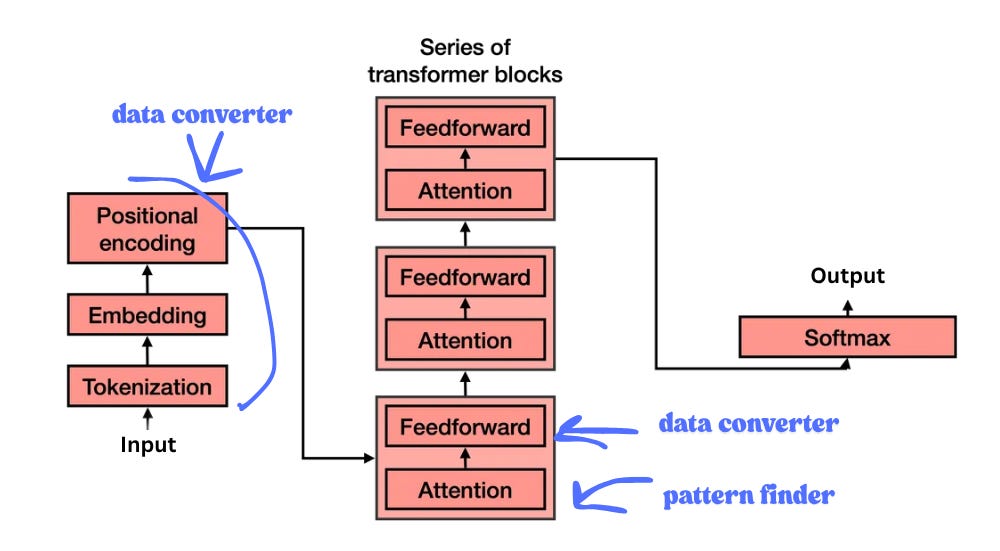
Step 1: Embeddings & Position. Words become numerical vectors (via tokenization). But transformers process all tokens simultaneously (no inherent order) so we add positional encoding. Think of it like row numbers in a spreadsheet: without them, the model can’t tell “dog bites man” from “man bites dog.”
Step 2: Self-Attention (Focus & Memory). Each word looks at every other word and decides which ones matter. Processing “sat” in “The cat sat on the mat”? The model figures out “cat” is the critical context — it’s the thing doing the sitting.
It works like search: Query (what you type into YouTube’s search bar) × Key (the video descriptions, tags) = attention weights. Those weights mix the Values (videos themselves). The transformer computes how compatible each Query is with each Key (like a search engine ranking relevance) then combines the relevant Values.
This is how transformers build focus (attention weights) and memory (accessing context across the entire sequence).
Step 3: Multi-head Attention. Runs this multiple times in parallel. One head finds subject-verb relationships. Another tracks modifiers. Another captures positional dependencies. The model discovers these roles during training.
Step 4: Feed-Forward Layers. Extract patterns from what attention found. Think of attention as reformatting, feed-forward as pattern recognition.
Why transformers won
Before transformers, you chose between bad options. RNNs processed sequences one token at a time — slow to train, information faded over long distances. CNNs processed in parallel but only saw local patterns within their window size (hence used for image recognition).
Transformers eliminated the tradeoff. Every token can directly attend to every other token in one step. Processing “The cat sat on the mat”? An RNN passes information through each word sequentially. A transformer lets “mat” directly attend to “cat” — distance doesn’t matter.
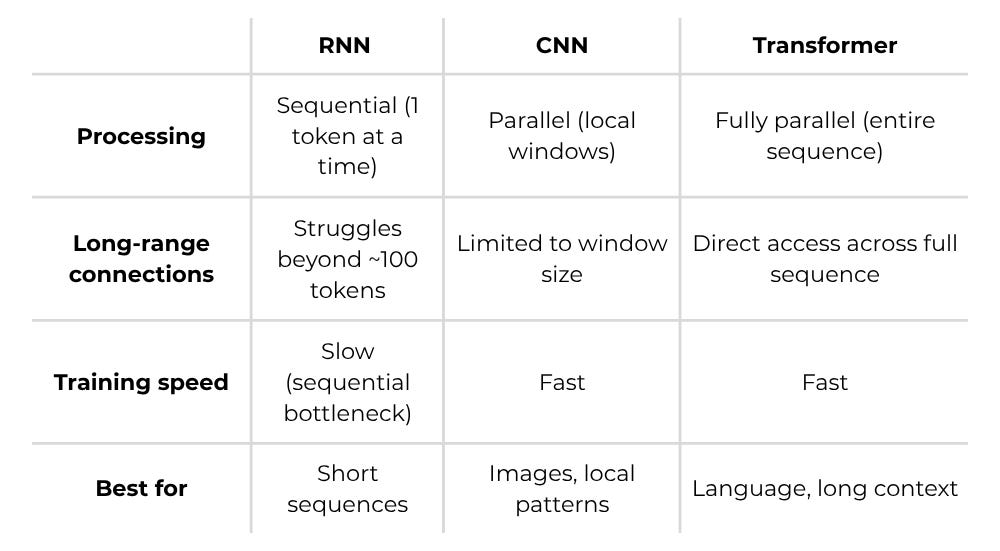
This is why transformers scaled and everything else didn’t. Parallelization (+ more powerful chips) enabled faster training. Direct attention enabled longer contexts. Together they made ChatGPT, Claude, and every modern AI model possible.
What I Actually Built
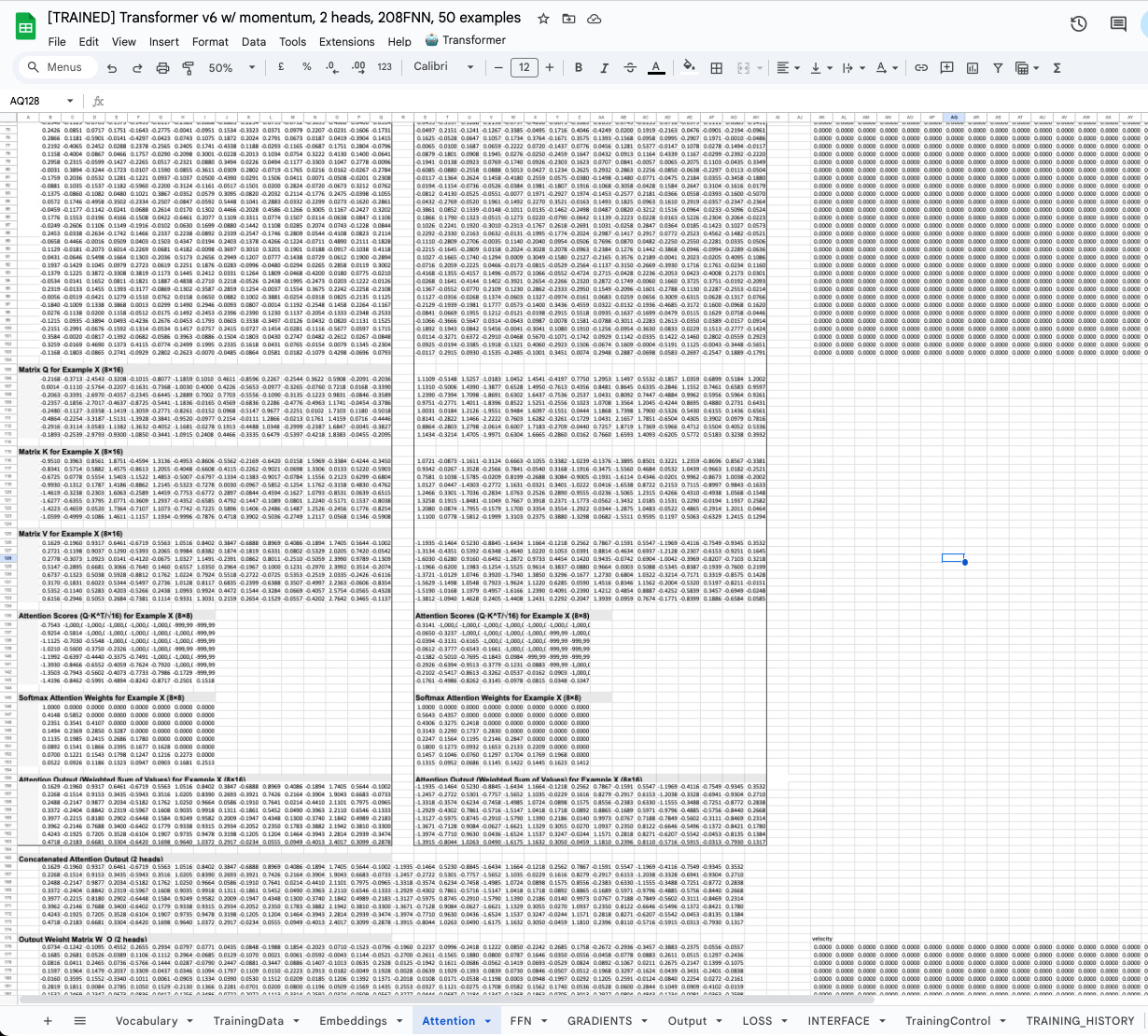
The architecture is a real GPT-style decoder-only transformer:
1 transformer layer
2 attention heads (16-dimensional each)
32-dimensional embeddings
208-dimensional feedforward layer with GeLU activation
Sequence length of 8 tokens
50-word vocabulary
~19,000 trainable parameters
For perspective, GPT-2 Small (OpenAI’s 2019 model) has 124 million parameters across 12 transformer layers with 768-dimensional embeddings and 12 attention heads. My spreadsheet version is roughly 6,500 times smaller. But the architecture is identical: multi-head attention, feed-forward layers, tokenizer. The same mechanisms that power ChatGPT, just scaled down to fit in cells you can inspect.
All of it trained on 411 simple cooking instructions like “heat big pan with the oil” and “mix two egg and flour in bowl”. I deliberately chose a narrow niche with limited vocabulary — cooking verbs (heat, boil, mix, fry, bake), ingredients (egg, rice, chicken, butter, water), and kitchen items (pan, pot, bowl, plate, cup). The goal was to build something small enough that I could actually trace every operation and understand exactly what was happening.
The training setup:
SGD with momentum (β = 0.8)
Token frequency weighting (rare words get stronger gradient signals)
Tied embeddings between input and output
411 training examples (hard to generate more training data with 50-word vocab)
Everything implemented in formulas across 11 sheets. Every gradient computed through formulas and iterative calculation. Every weight update visible in a cell you can click on and inspect.
Quick training primer
Neural networks are giant formulas whose parameters (weights) are learned from data. They make predictions by combining inputs through layers of weighted connections, and learning means adjusting those weights to make predictions more accurate. A loss function measures how far the predictions are from the correct answers. Gradients show how each weight should change to reduce that loss, and backpropagation efficiently computes these gradients by working backward through layers of the network. An optimizer then updates the weights based on the gradients, deciding how big each adjustment should be. The process repeats over the dataset many times (called epochs) until the loss stops improving or the model reaches a satisfactory level of performance.
What I Thought Would Happen
Weekend project. Maybe a week if backpropagation got messy due to spreadsheet iterative recalculations limitations.
The forward pass (model architecture setup) took 2-3 days. Matrix multiplications, softmax, attention heads, feed-forward network. Straightforward.
Backpropagation was harder but manageable. Chain formulas through every matrix, gradient accumulation, weight updates. I got it working.
The model didn’t learn.
What Actually Happened
Getting technical here — skip if you want.
A month of debugging. Not the code — the learning.
First version: 181 vocabulary tokens, 16-dimensional embeddings, single attention head, standard SGD. Loss declined for maybe 2 epochs. Then zigzagged. Then collapsed.
Each fix required reworking formulas, waiting for recalculation (5-7h full training run!!), watching the loss curve.
Layer normalization: Some stabilization. Zigzagging continued.
Momentum: First real win. Standard SGD updates weights based purely on current gradient: `W = W - α * gradient`. Every example pushes wherever its gradient points. Erratic.
Momentum accumulates: `V = β * V + α * gradient`, then `W = W - V`. Multiple examples pushing the same direction? Momentum builds and accelerates. Oscillating gradients? Momentum dampens the zigzag. The optimizer was “committing” to directions that consistently improved loss.
More capacity: Expanded from 16 to 32 dimensions. One → two attention heads. Significant spreadsheet rework — remapping formulas, expanding matrices. Marginal improvement.
Token frequency weighting: The model predicted “END” and “the” for everything. Literally everything. Most common token wins. Training longer didn’t help. Higher learning rates didn’t help.
I weighted the gradients. Common words like “the” and “in” get 2-5x weight. Rare words like “girl” and “book” get 10-25x weight.
Got a noticeable difference. The model learned the full vocabulary distribution. It predicted “girl” or “boy” in the right contexts instead of defaulting to “the”.
Activation function: Switched from ReLU to GeLU. Incremental gains.
The actual problem: After weeks of experiments, I stepped back and looked at the numbers. The problem was twofold.
First: too many tokens. 181 vocabulary tokens. ~19,000 parameters. Each token was getting barely any gradient signal. With only 19,000 parameters spread across 181 tokens, each token got noise instead of meaningful updates.
Second: too many concepts. I initially trained on generic language: simple sentences like “girl reads a book” and “dog runs across the field.” Grammatically simple, but conceptually vast. Girls, dogs, books, fields, reading, running. Each concept needs its own embedding space, its own attention patterns, its own relationships. With 19,000 parameters, the model couldn’t learn all of these disparate concepts simultaneously. It was trying to understand the entire world with a calculator’s worth of capacity.
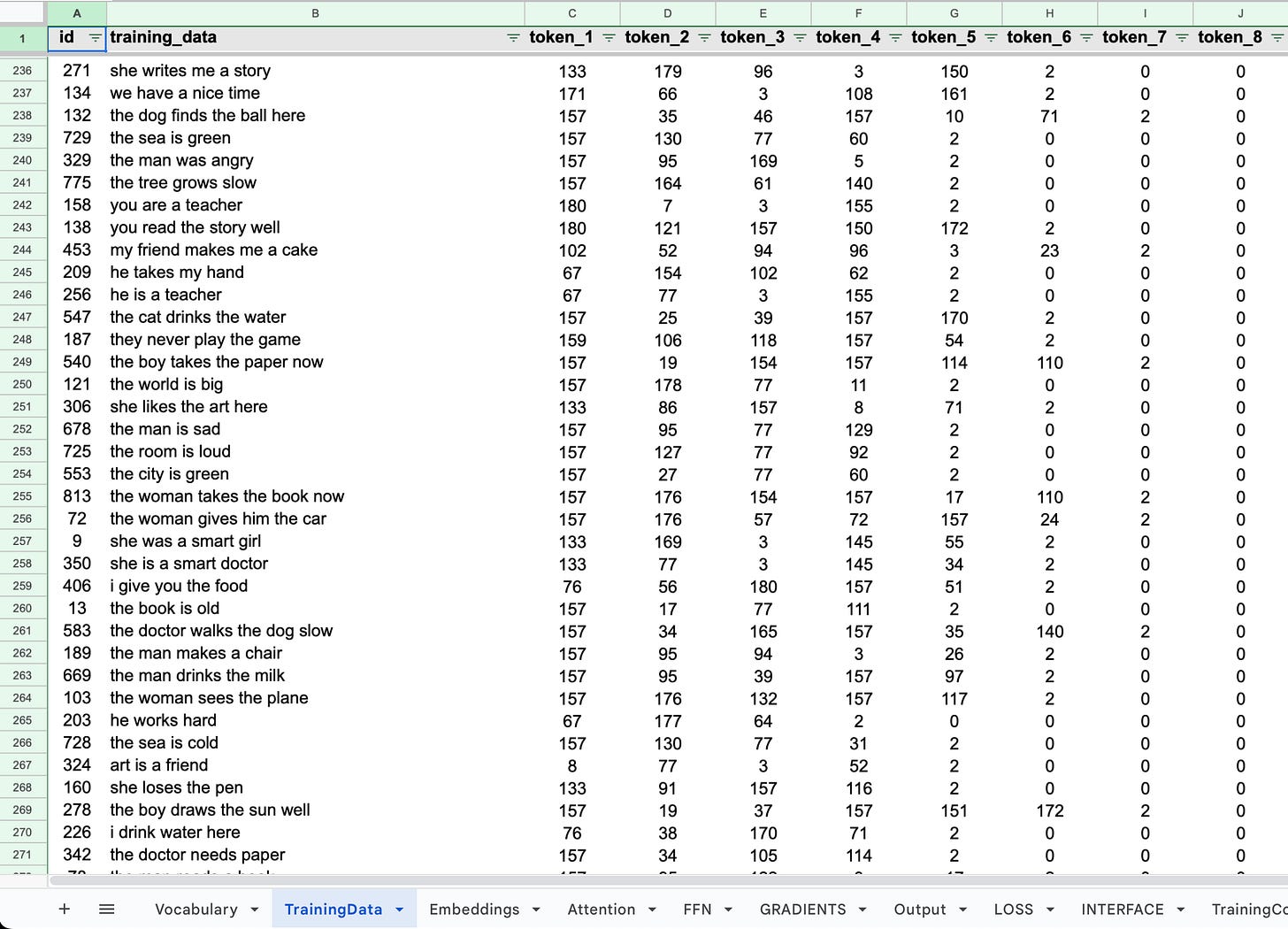
I made two changes: reduced vocabulary to 50 tokens and switched to cooking instructions. One narrow domain. Cooking verbs (heat, boil, mix), ingredients (egg, rice, chicken), kitchen items (pan, pot, bowl). Dense, repetitive patterns. “Heat the pan,” “boil the water,” “mix the egg.” The same relationships appearing hundreds of times.
This was the breakthrough!
Here’s what frameworks hide: In PyTorch, when training fails, you tweak hyperparameters and guess. In the spreadsheet, I could see exactly how gradients distributed across vocabulary. With 181 tokens and generic concepts, each token got noise. With 50 tokens in a focused domain, each got meaningful, consistent updates. The model finally had enough capacity per concept to learn patterns.
What It Learned
9 hours of training. 5 epochs through 411 cooking instructions. Loss started at ~4.5, stabilized around 2.5-3.0. A 40% improvement.
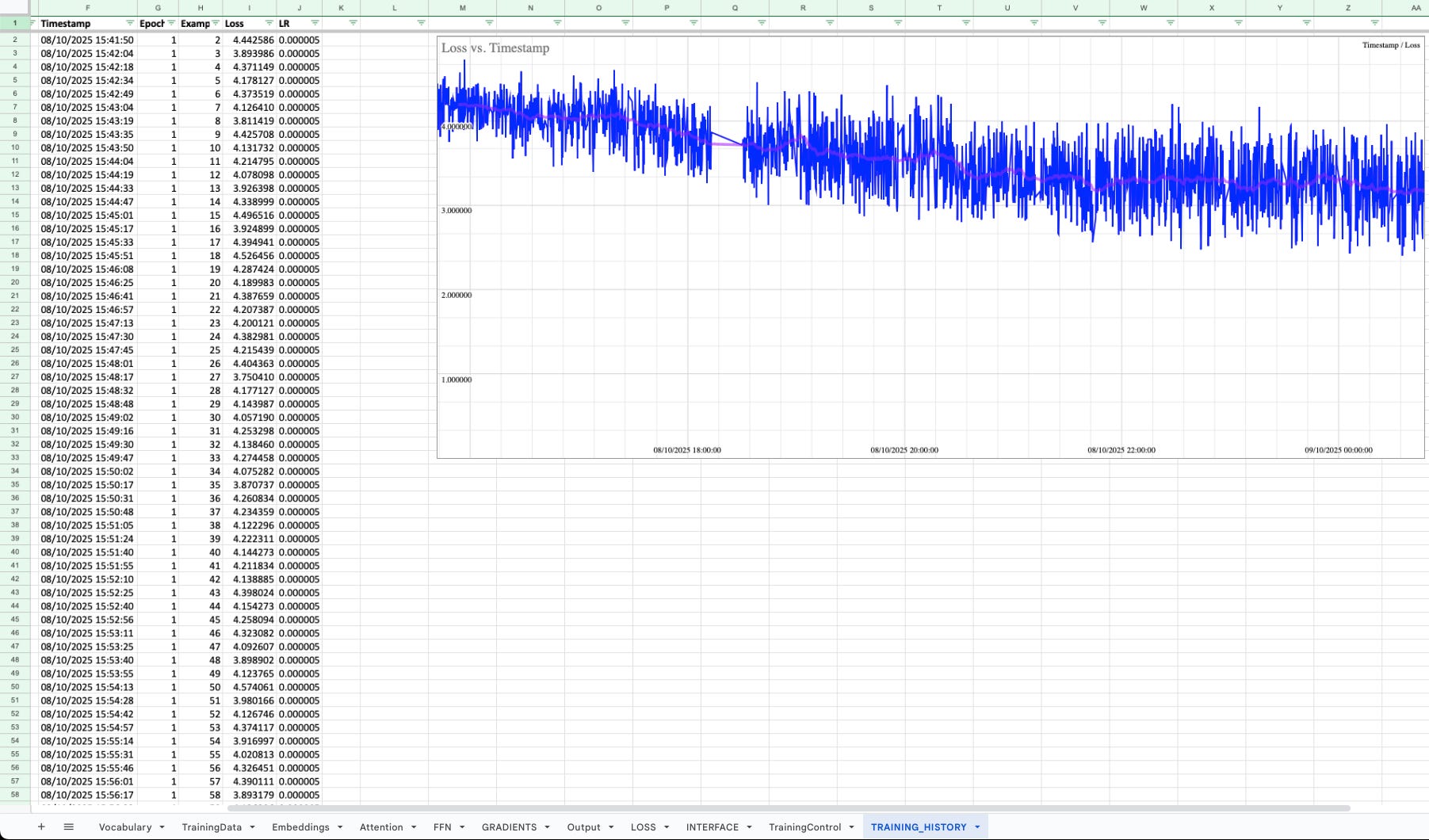
The two attention heads specialized without any explicit supervision.
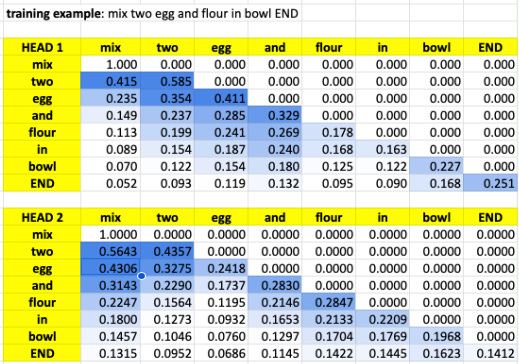
Head 1 learned syntax. It spreads attention smoothly across local context windows — 3-4 neighboring positions with weights around 0.15-0.35. Processing “flour” in “mix two egg and flour in bowl”? Head 1 distributes attention across “two” (0.199), “and” (0.269), “flour” (0.241). Grammatical structure.
Head 2 learned semantics. Sharp, focused peaks on critical words. When “two” appears, Head 2 ignores the adjacent “egg” and locks 44% attention on the verb “mix,” 56% on itself. The model discovered that quantities modify actions, not just ingredients.
This pattern repeats. Ingredients attend back to cooking verbs: “egg” → “mix” (43%), “flour” → “mix” (22%). The word “and” coordinates between “egg” (28%) and “flour” (23%).
Head 1’s attention entropy averages ~1.8 (distributed). Head 2’s averages ~1.2 (focused). One tracks syntax. One extracts meaning.
Generation examples:
- “heat the” → “heat the pot pot chicken hot in chicken”

- ”boil” → “boil the egg with chicken chicken”

The model learned the template: [verb] [article/quantity] [ingredient/tool] [preposition] [location/ingredient]. It knows “heat” gets cookware. “Boil” gets ingredients. Prepositions connect phrases.
It also repeats words (”pot pot”), makes nonsensical combinations (”chicken hot”), and loops (”chicken chicken”). These are the expected limitations of 19,000 parameters trained on 411 examples.
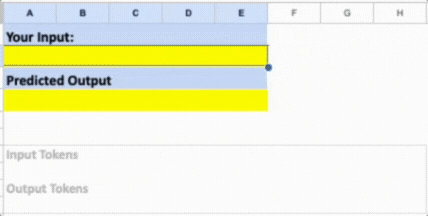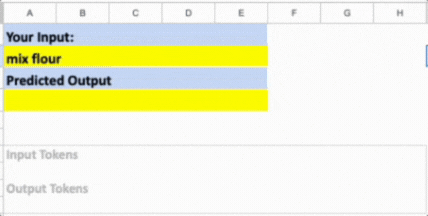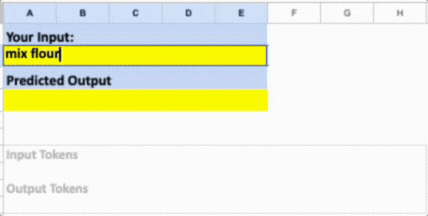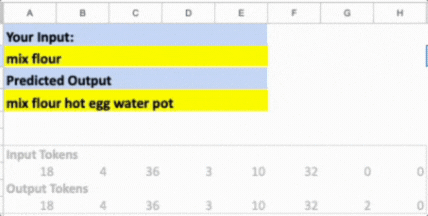
Another example: ”mix flour” → “mix flour hot egg water pot”. The model correctly maintains the cooking verb and ingredient, then generates a plausible expansion. It knows “mix” pairs with multiple ingredients (”egg”), uses liquids (”water”), and mentions containers (”pot”). The word “hot” is odd but reflects the model’s exposure to temperature-related cooking patterns. The sequence follows training structure even if it’s not quite human-level recipe writing. You can see both what the model learned (cooking domain structure, ingredient/tool relationships) and where its limitations show (random insertion of “hot”, no clear recipe coherence).
For comparison, here’s how GPT evolved from 117 million parameters (GPT-1, 2018) to hundreds of billions (GPT-4.5, 2025):
The spreadsheet model is 6,500 times smaller than even GPT-2 Small. But it learned enough to showcase how the architecture works. That modern AI (for all its apparent magic) is just matrix multiplications. And even a spreadsheet can implement those.
Why This Matters
Google Sheets will never compete with PyTorch. 9-hour training runs make that clear.
But when you implement backpropagation by hand, you understand the entire architecture differently. Every gradient is a number in a cell. Every weight update is visible. If your math is wrong, the model doesn’t learn. No stack traces. No helpful error messages. You trace through formulas yourself until you find it.
This is inefficient and incredibly valuable.
The architecture of modern AI is math, not magic. When you implement that math without abstractions, patterns emerge that frameworks keep invisible.
The best way to understand complex systems is to build them with constraints that force visibility.
In this case, that meant a spreadsheet.
Try It Yourself
The GPT SHEET is public. You can explore every formula, modify the architecture, and watch the model generate text.
Note: This is the inference version only — you can run inference but not retrain it. The full training version with gradients and backpropagation is much heavier. If you want to experiment with training, DM me and I’ll share it.
Resources that made this possible:
- LLM Visualization - really good interactive 3D visualization of transformer architecture
- Let’s build GPT: from scratch, in code, spelled out - by OG Karpathy
I completely get what you mean. That drive to truly understand the mechanics beyond abstracion is so important. Thank you for doing this 'stupid' thing, it's genuinely insightful and inspiring.