
Train Smarter, Not Harder
How I fine-tuned OpenAI model with real and synthetic data


AI's rapid progress relies on three pillars: compute, advancements in foundational models, and data. Compute power, driven by Nvidia, lets AI crunch through massive amounts of information. Advanced algorithms from research labs give AI new ways to learn and understand.
But here's the kicker - I believe the key for position of power for companies (both in application development and model creation) will increasingly shift towards data ownership and quality. Data is the raw material AI needs to actually get smart. The leading foundational model companies have already scraped the entire web for publicly available data. Now, the next frontier lies in accessing and leveraging unique, high-quality datasets that aren't freely available online.
Companies like Scale.ai will create enormous enterprise value by developing systems to collect, curate, and leverage non-public data. Other players in this space, such as Labelbox and Snorkel AI, are working on data labeling and management solutions. Are there other options for businesses and researchers looking to enhance their AI models?
Here's the question I'm trying to answer: Can we accelerate models fine-tuning and improve an AI's ability to generate correct and contextually accurate responses by fine-tuning it with real-world and synthetic data? My hypothesis is that this hybrid approach will outperform models trained solely on real-world data or those relying on sophisticated prompt engineering with a base model.
Why does this matter? Well, high-quality, diverse real-world data for vertical use cases is hard to come by. It's limited, expensive to collect, and may not cover all scenarios needed for domain-specific applications. But what if we could supplement it with realistic synthetic data? We could fine-tune AI more effectively and efficiently.
In this post, I explain how I created a unique training dataset and fine-tuned the OpenAI-4o-mini model. I used OpenAI’s Instruction Fine-tuning approach, which improves the model’s performance by training it on a large set of examples tailored to specific tasks. As a result, the model delivers more consistent and accurate outcomes across a variety of situations.
Why the Future of LLM Training might be Combining Real and Synthetic Data
In my experience, real-world data is essential but has limitations. It's often messy, incomplete, and narrow in scope. That's where synthetic data comes in:
Scalability: Rapidly generate large volumes of diverse data
Customization: Create scenarios tailored to specific use cases
Edge Cases: Produce examples of rare but important situations
This approach is particularly valuable in vertical use cases, where we need to expose the model to a wide range of specific scenarios and interactions.
In my experiments (which may not generalize), this hybrid approach consistently outperformed both pure real-data training and sophisticated prompt engineering with a base model.
I use my CBT Therapy Counselor project as an example, but the principles apply to many fields.
The Data Strategy: How I Built a 500-Session Training Dataset
Real Data: 300+ Scraped and Transcribed Counselor Sessions
To build a solid foundation for the AI Therapy Counselor, I collected over 300 actual counseling sessions. Here's how I approached this:
Data source: I scraped CBT therapy session role-play transcriptions from a well-known video hosting platform. This provided a diverse range of publicly available therapy simulations.
Data processing: I cleaned and formatted the transcriptions into OpenAI’s .jsonl format, removing irrelevant information and standardizing the structure.
This real-world data approximated authentic CBT interactions, although it was not from actual therapy sessions. It formed the basis of my training set, anchoring the AI model in realistic scenarios. It also prepared the groundwork for synthetic data input in the project's next phase.
Overall, the flow chart below summarizes the synthetic therapy sessions.

Synthetic Persona Generation

I created a set of synthetic personas and counseling themes to expand beyond the limitations of real-world data. These were imaginary clients with varied backgrounds, personalities, and issues. This diversity was key to ensuring the AI could learn to interact with all kinds of people.
Creating Therapy Situations Based on Personas and Themes
Next, I created a separate script that generated unique therapy scenarios tailored to each synthetic person's character. For example:
"summary": "This scenario focuses on the challenges faced by young adults in managing ADHD in both academic and social settings. It highlights common cognitive distortions that can exacerbate their difficulties.",
"cognitive_distortions": ["Mind Reading", "Jumping to Conclusions"],
"scenario": "Emily is a 22-year-old college student at a large university in New York City. She was diagnosed with ADHD during her sophomore year. Despite starting medication and attending therapy sessions, she faces overwhelming anxiety and self-doubt about her academic performance and social interactions. Recently, Emily had a hard time completing a group project because she felt that her suggestions were ignored by her teammates. During their last meeting, Emily perceived that her teammates' silence meant they thought her ideas were foolish (Mind Reading). Due to this belief, Emily withdrew from contributing further, convinced that she was right and that they didn't value her input. Additionally, she received a 75% on her latest exam, lower than her usual grades. She immediately thought that this slip meant she would fail the course and, eventually, be unable to graduate (Jumping to Conclusions). These thoughts have led Emily to consider skipping classes and withdrawing from social interactions altogether."
"summary": "A woman experiences a low sexual frequency in her marriage and fears it reflects a deeper issue.",
"cognitive_distortions": ["All-or-Nothing Thinking", "Catastrophizing"],
"scenario": "Anna, a 34-year-old woman living in Chicago, has been married to her husband, Marcus, for seven years. Throughout their marriage, they have only had sex four or five times. Anna's friends have told her that most men would have left her by now, which has fostered a belief that her marriage is failing. She often finds herself in all-or-nothing thinking, believing either their relationship is perfect or it is doomed, with no middle ground. Additionally, Anna tends to catastrophize the situation, fearing that Marcus will leave her soon if things don't change, even though he hasn't shown signs of wanting to leave. Anna suspects that she has a low sex drive or that neither she nor Marcus knows how to improve their sexual relationship. She wishes to feel more connected to Marcus and improve their intimacy but feels overwhelmed and doesn't know where to start."
Generating High-Quality Synthetic Sessions
I created detailed therapy sessions based on these synthetic people and situations using another script that leveraged OpenAI API. I ensured these sessions were different lengths and covered various topics to help the AI learn to be flexible.

Data Evaluation and Cleanup
I also knew that even synthetic data needed a critical eye. To ensure quality, I developed a separate script that used an LLM to rank and evaluate each generated session. This process flagged sessions for manual review, allowing me to clean up inconsistencies or unrealistic elements.
The result? A final dataset of 500 diverse, high-quality therapy sessions. This hybrid collection combined the authenticity of real therapy transcripts with the controlled variety of synthetic scenarios, creating a rich training ground for my fine-tuned AI model.
Performance Analysis of Empathy and Relevance in Models

Model Selection
To understand how well different training approaches worked, I tested three different models. I used the same standardized prompt for each model to make the comparison fair:
Base Foundational Model (GPT-4o-mini): This model wasn't fine-tuned at all. It used only the original training and some smart prompt engineering to generate responses.
Real-Data Fine-Tuned Model: This version of GPT-4o-mini was fine-tuned using real counseling sessions that were transcribed. This helped provide realistic contexts for therapy interactions.
Hybrid Fine-Tuned Model: This version of GPT-4o-mini was fine-tuned with both real data from counselor sessions and additional synthetic data. The synthetic data was used to add more variety, covering situations that weren't in the real data.
Quantitative Measurement Approach
To evaluate these models with numbers, I followed these steps:
• Dataset Creation: I made a dataset of 50 unique therapy scenarios. These included different kinds of issues that people face, like anxiety, cognitive distortions, and problems in relationships.
• Simulated Conversations: Each of these 50 scenarios was used to create a conversation with each of the three models. The patient side of each conversation was simulated by GPT-4o to keep things consistent. Altogether, I had 150 conversations (50 for each model).
• Scoring Methodology: Each conversation was scored for empathy and relevance. I used a clear scoring prompt to evaluate the quality of the responses consistently and thoroughly.
• Data Analysis: I summarized the scores from all the conversations and analyzed them to see how each model performed, both in terms of average scores and how consistent those scores were. This analysis helped me understand the strengths and weaknesses of each model's ability to communicate effectively.

The hybrid model had the highest average scores for empathy and relevance, scoring 8.64 and 8.66, respectively. The base model scored 8.48 for empathy and 8.08 for relevance, while the real-data model scored 7.32 for empathy and 7.24 for relevance. These results suggest that using both real and synthetic data makes the model better at understanding users, leading to more empathetic and relevant responses.
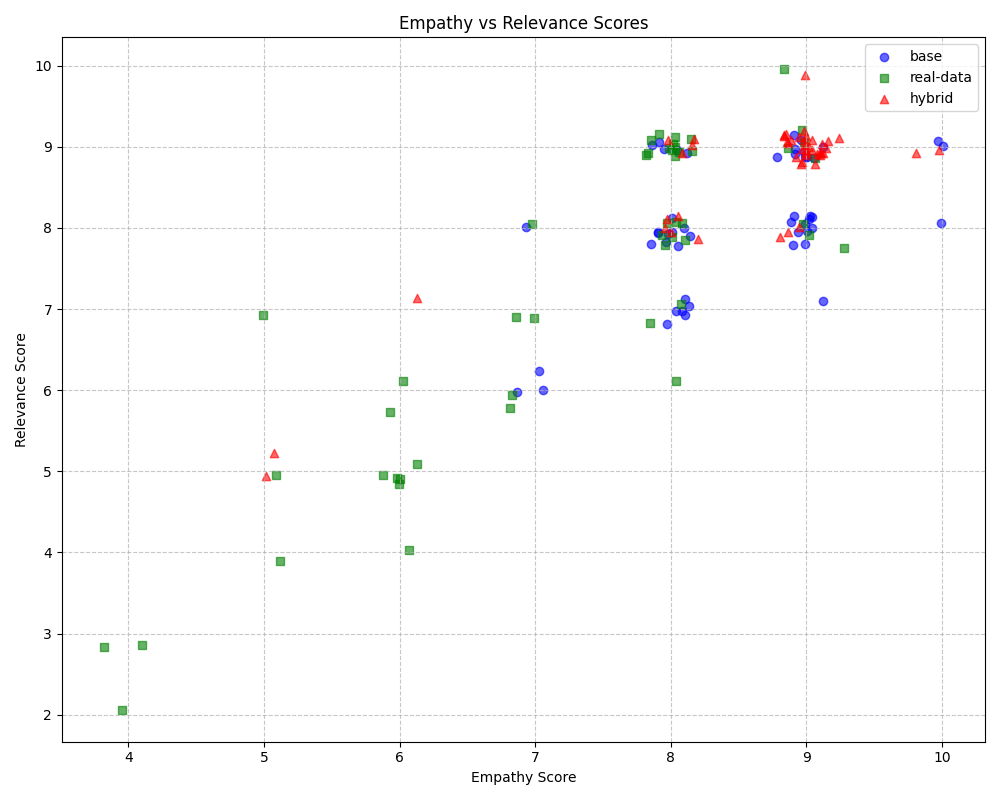
The real-data fine-tuned model had the lowest performance, and there might be few reasons for this. First, real-world data often has inconsistencies and noise, which makes it harder for the model to learn effectively. Also, real counseling sessions tend to focus on more common situations, meaning the model might struggle with less typical but still important issues. Because of this, the model fine-tuned only on real data wasn't as flexible in handling a wide variety of user inputs.
Overall Insights from Model Analysis
The analysis gave me some important insights into how the models compared to each other:
• Hybrid Model Performance: The hybrid model had the highest average and median scores for empathy, relevance, and combined metrics. This shows it was the best at delivering quality responses overall.
• Base Model Consistency: The base model had the most consistent scores for empathy, relevance, and overall performance. This could be because it wasn't affected by the variability that fine-tuning sometimes introduces.
• Real-Data Model Variability: The real-data model, even though it was trained on actual counseling sessions, showed a lot of variability in its performance. This was likely because of the inconsistencies in real-world data, which made its results less predictable compared to the other models.
These insights suggest that while fine-tuning with real data gives the model a sense of real-world context, it also makes the model's performance less consistent. On the other hand, the hybrid model, by adding diverse synthetic data, helps reduce some of these issues, resulting in more consistent and better-quality responses. However, there's still a chance that the hybrid model could overfit in some rare cases, especially when the synthetic data doesn’t fully capture real-world variability. To avoid this, using an even more diverse set of synthetic data might help ensure the model stays strong without overfitting to specific, less common scenarios.
Initial Qualitative Testing and Real-World Validation
To build on the quantitative findings, I analyzed around 200 real conversations between users and the AI Therapy Counselor, and these gave me some valuable insights into how the models performed.
From the initial testing, the hybrid model stood out as the best. It showed a deeper understanding of the therapy framework, used therapeutic techniques more effectively, and gave more contextually appropriate responses. Adding synthetic data really helped fill in the gaps, allowing the model to handle a much wider range of situations.
One of the biggest improvements I noticed was how well the hybrid model managed longer conversations. It knew when to shift topics or suggest wrapping up a session—an important skill in effective therapy. This real-world validation backed up what I found earlier: the hybrid model outperformed the other models.
The hybrid model excelled in several key areas:
Identifying and addressing unhelpful cognitive patterns.
Providing empathetic responses tailored to each user's situation.
Staying consistent during longer conversations.
Recommending effective therapy techniques and exercises.
These observations matched up with the quantitative data, reinforcing the power of the hybrid approach. Combining real and synthetic data not only led to the highest average scores but also brought significant improvements in real-world conversations. The hybrid model showed it could handle complex therapeutic interactions, offering appropriate and empathetic responses while keeping conversations coherent, even during longer sessions.
Conclusion: Where Do We Go from Here?
My experiment showed that using real and synthetic data might work better for fine-tuning LLMs than just using real data. Here's why this is important:
It helps the AI learn about more situations, even ones without real data.
We can control what the AI learns to cover all the important details.
This method could work for other fields, not just therapy.
I believe the key to better AI isn't just having tons of data. It's about having the right mix of data that covers all the bases. This "smart data" approach could change how we train AI in the future.